





Every one of these was generated by AI. Each was created in the style of a different artist, chosen to match that city’s unique history and culture. No stock illustrations, no sterile filters. The AI wasn’t just generating an image; it was choosing an aesthetic and executing it.
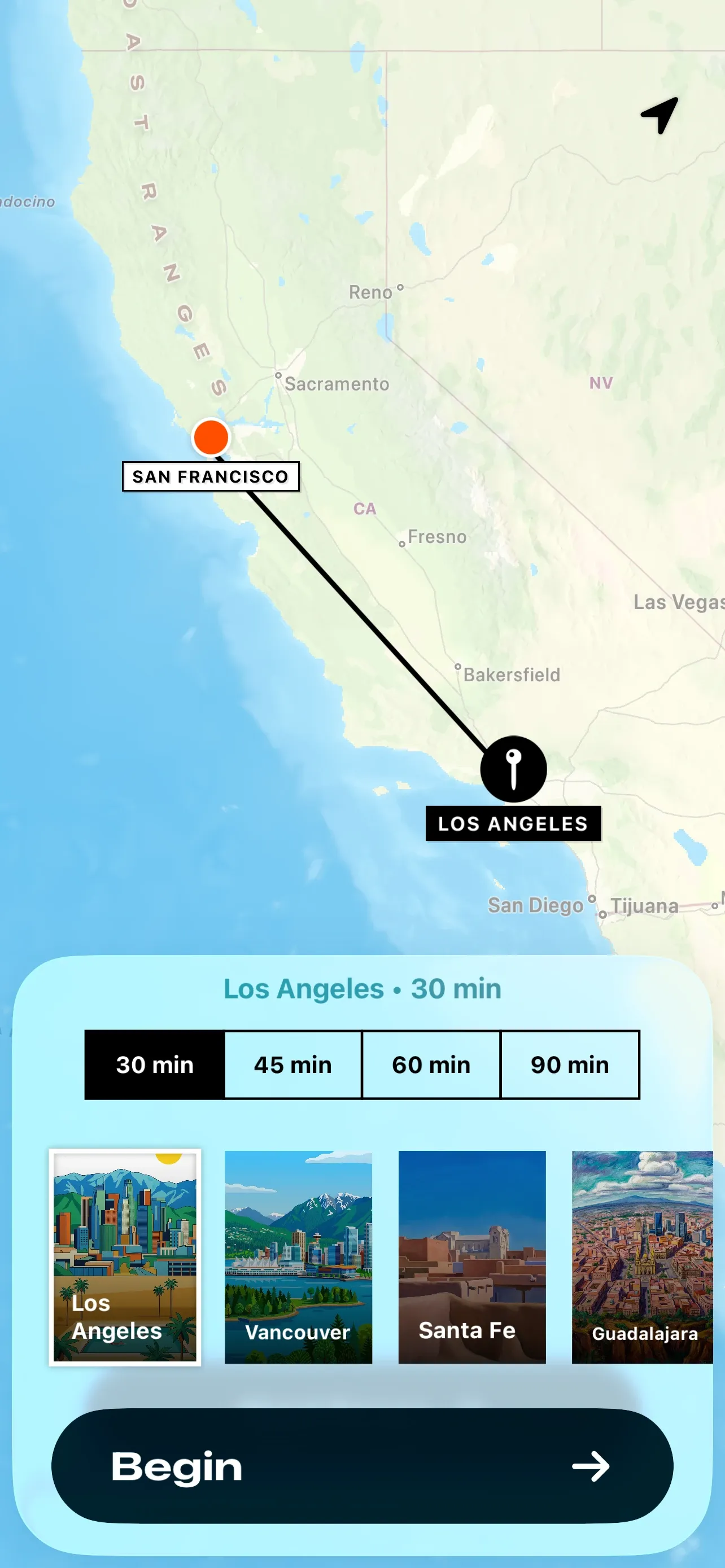
I built this for ExploreFocus, a focus timer where every 30-minute session unlocks a reward: a postcard from a different corner of the world. I wanted that reward to feel like pulling a rare find from a vintage rack, not a generic image from a search engine.
Getting there took almost a year, several thousand dollars in API credits, and a breakthrough from a model I hadn’t even considered.
Almost a Year and Several Thousand Dollars
My original plan was simple: a weekend project. Pick a model, write a good prompt, and batch-generate the collection.
I started with the industry giants: Midjourney, Recraft V3, GPT-image-1. But every model eventually hit the same wall, just in different, frustrating ways.
Factual accuracy — models hallucinate landmarks.
AI models are notoriously bad at architecture they haven’t properly internalized. Ask for a famous landmark and they’ll hand you something that looks plausible at a glance (even confident) but is fundamentally broken in its details. At first, I thought I was just asking the wrong way. I wasn’t.



Detail — models render structure, not soul.
GPT-image-1 looked more promising at first. Fewer hallucinations, and with regeneration I could fix the rare mistake. But the images were flat. Structurally plausible, but no texture, no character, no sense of place. You could look at it and have no idea which city it was.



Stylization — models ignore the artist.
I needed thousands of distinct artistic styles, each matched to a named artist.
The same prompt would produce completely different results. I asked Midjourney to paint Shanghai as Wu Guangzhong, a master of lyrical ink-wash with dancing black lines and scattered color dots, and ran the same prompt twice. Two entirely different styles came back, neither of them Wu Guangzhong.


GPT-image-1 had the opposite problem: it didn’t vary at all. It would latch onto a generic house style and apply it to most cities. Less famous cities especially ended up looking identical: same cartoon tone, same palette, same brushwork. Thousands of postcards that all felt like they came from the same place.




4 different cities, same style. GPT-image-1 defaulted to the same heavy expressionist palette regardless of the artist specified.
By this point I had tested Recraft V3, Flux, GPT-image-1, Midjourney, and probably a hundred prompt variations. Thousands of images generated. A lot of money gone. Every model had failed in its own way. Confidently wrong about the world, or technically correct but completely characterless, or locked into the same style regardless of what I asked.
I was close to accepting that no existing model could do all three things at once. Then Google released a new model: Nano Banana Pro (gemini-3-pro-image-preview). I ran my first batch half-expecting the usual disappointment. The landmarks were right. The light felt right. I scrolled through the whole batch before saying anything. That was the first batch I hadn’t been scanning for what went wrong.








The Monet Problem
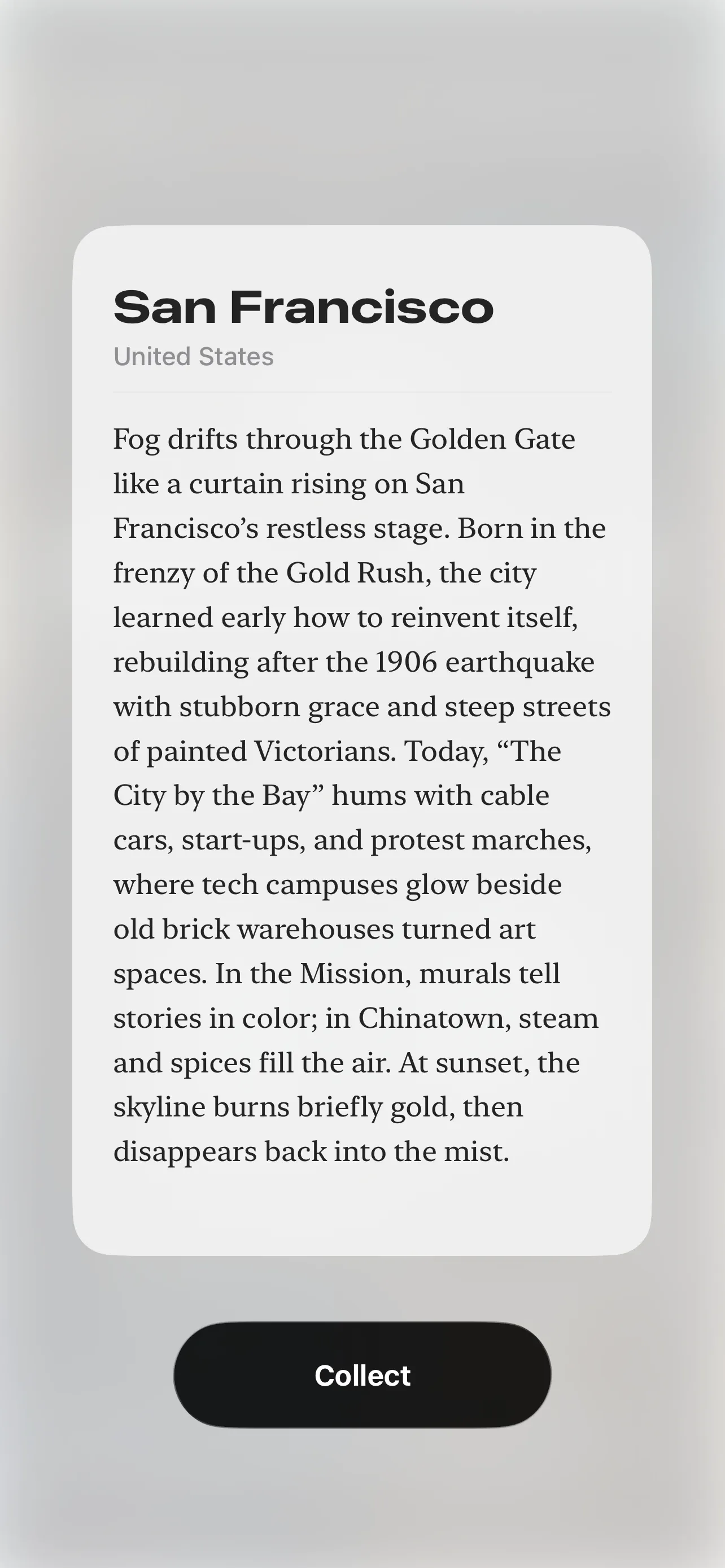
Every city needed an artist who belonged to it: Monet for Paris, Hopper for Chicago, Turner for London. I built an agent that, given a city, would research a regionally matched artist and generate a tailored prompt.
The problem? Left to its own devices, the model developed strong preferences. Turner would show up for over twenty different cities. Monet would cover half of Europe. When I looked at the full list, the same handful of names kept recurring. The model had collapsed toward its most frequent training associations, regardless of what I’d asked.
I tried fixing this through the prompt, pleading for diversity: pick regional artists, avoid repeats, and explore the unconventional.
Given the city {city}, {country}, find an artist whose style and cultural background best represents it. Prioritize artists native to or historically connected with the region. Ensure diversity across the full collection and avoid repeating popular artists like Monet or Turner.It didn’t work. Turner kept coming back. The model had no concept of its own history; each city was a fresh request with zero shared context.
The breakthrough was introducing a “memory layer.” Instead of treating each city as an isolated request, the agent now checks the database first. It sees who has already been “hired” (Turner for the 21st time, Monet for the 14th) and treats that list as a strict exclusion zone.
The prompt became:
The following artists have already been used. Do NOT select any of them:
J.M.W. Turner (x21), Claude Monet (x14), Winslow Homer (x8) ...
Given the city {city}, {country}, find an artist whose style and cultural background best represents it. Prioritize artists native to or historically connected with the region. Ensure diversity across the full collection.It worked. Monaco got Tamara de Lempicka. Marseille got Paul Signac. Lyon got the Lumière Brothers, who were born there. Cologne got Gerhard Richter.




The Rules You Don’t Know You Need
The diversity problem was solved. The model started producing things nobody asked for, and some of them were almost impressive:



The model, deeply committed to the method-acting approach, would sign paintings in the style of whichever artist it was imitating. Another favourite: framing the whole image as if it were already hanging in a gallery. Thoughtful, and completely unwanted.
These didn’t emerge one at a time. A batch would come back with signatures, frames, and hallucinated text all at once. Fixing them took multiple runs: patch what you can see, run again, find what you missed. What I accumulated over those iterations was essentially a negative prompt list: no text, no signatures, no borders, no frames. Each line something I hadn’t thought to forbid until I saw it.
Building the Wrong System First
I had a working model, a working artist system, and a growing list of constraints. Now I had to run the whole thing across hundreds of cities without it falling apart.
My first instinct was to build a traditional pipeline: a linear sequence of steps, each with its own error handling, retry logic, and database state management. I started writing code to handle every edge case manually:
- API rate limits and network failures leaving jobs in a broken state
- Generated images with factual or style issues that needed flagging and regeneration
- Dynamically adding or removing cities mid-run without disrupting the rest
I wasted real time on this. The logic kept growing. Every new edge case needed more code.
Somewhere in the middle of writing another retry handler, it hit me: what if I just let the agent run the whole thing? I scrapped the pipeline and gave it tools instead.
Surprisingly, it worked much, much better than the rigid workflow way. Adding a new city went from a code change to a simple message: “add a city in Southeast Asia.” It would query the existing list, pick something that filled a gap, and run the pipeline on its own.
Lessons
This project started before every tech blog was filled with “agentic” workflows. At the time, giving an AI tools and memory and letting it reason through a problem felt like an experiment, not a standard library. It changed how I think about software engineering.
- Prompt engineering is about constraints, not magic words. It used to be about finding the “right” phrasing. Now, it’s about guiding. Giving AI total freedom makes it lazy; it gravitates toward its most frequent training data. Adding strict guidelines is what actually forces it to be creative.
- The future of engineering is agentic, not linear. Rigid pipelines are brittle; they shatter when data gets messy or requirements shift. An agent equipped with memory and tools doesn’t just process; it adapts. It can query what’s done, bridge gaps, and recover from failures without human intervention.
- Iteration and testing are non-negotiable. Building a reliable agentic system means fighting something smart but probabilistic. Models can be brilliant in general and specifically wrong: the wrong landmark, the same artist twenty times, or a signature that ruins the art. Building a way to review outputs and iterating on those failures isn’t “extra work”; it’s the core of the engineering process.
In my first drawing class, I drew a Hello Kitty, carefully and proudly. My classmates were quick to inform me it was a rather unmasculine choice. I don’t think I picked up a pencil with that kind of joy again.
I still can’t draw. But I spent months choosing artists, writing prompts, watching paintings come back from cities I’ve never visited. I don’t know what to call that, but it felt like something.
Appendix
About ExploreFocus
ExploreFocus is a Pomodoro-style focus timer for iOS. Every 30-minute work session unlocks a postcard from a city somewhere in the world, illustrated in the style of an artist native to that region. The postcards are collectible, the collection grows over time, and the reward is designed to feel like pulling a real piece of art from a vintage rack.


What If You Used the Wrong Style?
The system matches artists to their home cities. But what happens when you deliberately break that rule and paint Amsterdam in Chinese ink-wash, or New York through a Japanese woodblock lens?





The mismatches are often more interesting than the correct pairings. Chinese ink-wash catches Amsterdam’s canals in a way no Dutch Golden Age painter would have thought to try. The American diner aesthetic fits Tokyo so naturally it stops feeling like a mistake.
Picking the Right LLM for Storytelling
Each city also needed a ~100-word cinematic description. I tested Claude, Gemini, GPT, Grok, Qwen, and others. What I found is that every model has its own distinct “taste,” a default voice it gravitates toward regardless of the prompt. GPT is stiff and structured, resistant to stylistic direction. Gemini is fluent but empty; beautiful sentences that say nothing specific. Grok hits the sweet spot of cinematic tone with dense facts, though it’s less consistent at following the prompt structure.
London, as written by GPT and Gemini:
GPT
Roman Londinium grew around a river crossing, its timber wharves feeding markets and, after the Great Fire of 1666, Christopher Wren’s spires rose like new compass points. In coffeehouses, marine risks were tallied and stock prices chalked, seeding Lloyd’s and the Stock Exchange. Today, the Square Mile and Canary Wharf hum with screens where code prices the tides, while studios, stages, and labs from Soho to King’s Cross test ideas before the world. The Tube’s refrain — Mind the gap — could be the city’s creed: a place that bridges old lanes and bold skylines, Dickensian alleys and The Shard’s edge, turning trade and conversation into its enduring glow.
Gemini
From a bustling Roman trading post on the Thames, London grew beyond its ancient walls, ceaselessly redefining itself. Its enduring heart remains a nexus of global commerce, where the Square Mile orchestrates international finance and tech hubs sprout new futures. Simultaneously, the city’s vibrant cultural districts, from West End theatres to cutting-edge galleries, draw millions, embodying its celebrated blend of tradition and avant-garde. This ceaseless pulse of innovation and heritage ensures London remains a dynamic, influential world city, constantly evolving, forever captivating.
When asked to generate in Chinese, GPT-5’s output became nearly unreadable, feeling stilted and machine-translated. Gemini, by contrast, produced genuinely elegant prose in Chinese, and its voice stayed consistent across both languages. For a multilingual product, that’s not a small thing.
Gemini — London in Chinese:
伦敦的故事,始于古罗马的伦丁尼姆,一个泰晤士河畔的边陲贸易站。历经千年风雨,它从”雾都”的传奇中走出,蜕变为全球金融的心脏、创意产业的沃土和顶尖学府的聚集地。这座古典与现代交织的城市,大本钟的古老钟声与创新脉动并存,是名副其实的多元文化熔炉。伦敦,以其独特的包容与活力,持续书写着世界级都市的辉煌篇章。
GPT-5 — London in Chinese:
当罗马人在泰晤士潮汐边插下一枚桩,称它为伦迪尼姆,商旅顺水来。火与雾锻过骨骼,木梁化作石街,仓栈蜕成玻璃群岛,旧船坞点亮金丝雀夜。莎翁回声在西区延续,硅环岛光标与交易钟声交错,令雾都心跳由资本、代码与戏曲合奏。
The GPT Yellowish Image Problem
Look back at the GPT-image-1 examples earlier in this article. They all share something beyond the style drift: a warm, muddy, yellowish cast over everything. It’s not a coincidence.
This is a well-documented issue. Search for it and you’ll find threads of developers attempting the same fixes: style instructions, lighting descriptions, and post-processing. None of them reliably worked.
Surprisingly, adding "color temperature 6500K" to the end of every prompt helps. 6500K is daylight-balanced white; it nudges the model away from its warm default and toward something more neutral. Not a perfect fix, but noticeably better.